NOMAD Infrastructure
By fawzi
High level
The NOMAD Archive and Analytics infrastructure consist of many pieces.
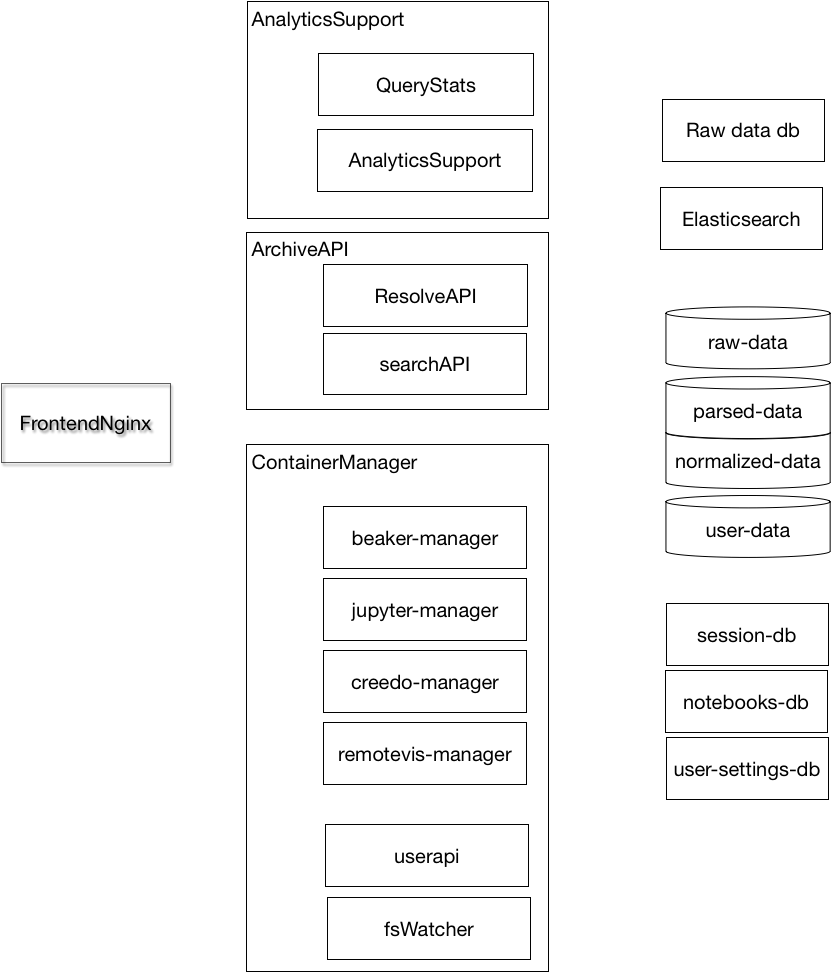
For a user it is a web application. We expose several services using a web proxy, as discussed in frontend page. The services themselves are are provided using Kubernetes and Docker. In the kubernetes page we discuss the advantages and disadvanteges of such an approach, and how to set it up. Detailed deployment instructions are given in the deploy page
Storage
Storage is central Big Data infrastructure.
All the file based data is organized in a series of paths (by default starting at /nomad).
The NOMAD Archive data paths are places where files containing the data of the NOMAD Archive. The files are named using the archive gid and extension: <3 letter prefix of the gid>/<gid>.<ext>
/nomad/raw-data/data: place where the raw data zip archives are stored (gid:R*, ext:zip)./nomad/parsed-data/prod-<version>: place for the HDF5 files generated by the parsers of the version <version> of nomad-lab-base (gid:S*, ext:h5)/nomad/parsed-data/productionH5: place for the current parsed HDF5 files (points to the current version)/nomad/normalized-data/prod-<version>: place for the normalized HDF5 files generated by the parsers of the version <version> of nomad-lab-base (gid:N*, ext:h5)/nomad/normalized-data/productionH5: place for the current normalized HDF5 files (points to the current version)
Beside the data of the NOMAD Archive there are places for user data. These are
/nomad/user-data/private/<user>: user data visible only to the user <user>/nomad/user-data/shared/<user>: user data readable by all users
Finally there is a place for supporting data for the various services: /nomad/servers/<hostname>/<service>
Given the experience of Garching with IBM Spectrum scale (ex GPFS) we went with a simple shared file system approach for all this data.
There are other options which might be interesting for the future. For example recently Kubernetes introduced persistent volumes and persistent volume claims to virtualize also the storage, which can be interesting especially for the supporting data. This was not available when we started, but now it is available in all commercial kubernetes installations (open shift, azure, amazon, google compute). If one roll his own (as we do) it has to be installed on the top of the kubernetes installation. ceph looks like one of the most mature open solutions.
For the NOMAD Archive data, if one would like to use the Hadoop environment HDFS is an obvious option. ceph also supports object storage (that can be used also with the S3 API), and could be used as the source of truth for the Archive data.
General Services
Aside from kubernetes a couple of general services are suggested
- helm: a tool to simplify the deployment of multiple services. This is required to deploy some standard software. It would make sense to use it also for our deployment, but due to some reservations about its usage by csc we delayed using it
- prometheus: a tool to monitor the various services
- nexus: A repository for jars, and docker registry. It is one of the few open source secure docker registry. For this reason we used it, but it represents a single point of failure, and trying simplify management we tried to witch to gitlab (that added docker support).
Container Manager
Container manager is the way we give users own containers. It is described in detail in its webpage.
beaker-manager (/beaker, served by the nomad-container-manager-beaker service), jupiter-manager (/jupiter, served by the ), creedo-manager (/Creedo) and remotevis-manager (/remotevis) give access to different applications/containers.
watcher-manager checks the filesystem and keeps a database describing the notebooks found up to date.
userapi-manager exposes information on the current user, notebooks, and storage usage through a jsonapi API under the /userapi prefix
Supporting Services
Whenever possible we did try to use existing software to solve our problems, we have to focus on the things that we need to do, or where we can make a difference. Relying on mature software when possible is the best option.
We use postgres as efficient open source relational database. 9.6 improved support for upserts and json, that is our current choice for rawdatadb: the place where we store information on the raw data archives.
elastic search provides search and indexing for the archive (and the repository). It is vailable as the elasticsearch service.
MongoDB was one of the first open source large non SQL database, we use it (a bit due to historical reasons), to store information on the user generated notebooks in the notebooks-mongo service.
Redis is a fast distributed key-value store. We use it for sessions and extra user info. Setup performance and use have always been satisfactory.
RabbitMQ is used as queue system to generate the normalized data.
Archive
The archive gives access to the public data of the NOMAD Repository. The lowest level gives access to the bulk data of the repository and the processed data in HDF5 (and as test) in the parquet format. That happens with a plain old static http server at http://data.nomad-coe.eu.
The raw data itself is stored in the BagIt format (zip files containing a payload (raw files), checksums and extra information on the data), which guarantees long term accessibility and verifiability. The name of the Bag itself is derived from the checksum of the data it contains, with a prefix (R) that defines the type of checksum/object. HDF5 and parquet files are named with the name of the Bag they are derived from, but with a different prefix (S for parsed data, N for normalized data). The organization is the one described previously in Storage, and the storage itself was done as said with GPFS, but an object storage like amazon S3 would also work.
There are two main services to make the data available in a better way.
Resolve Api
resolve api can return the data corrsponding NOMAD URIs, i.e. unique URIs that can identify any piece of data that is stored in the archive. It does that accessing the HDF5 files containing it, and returning the data corrsponding to them in json format.
Query Api
NOMAD URIs can be used to find related data, but how to find the uris one is interested in in the first place? The Query API does this using that data indexed with elastic search, and returning and overview data and the NOMAD URIs corresponding to it.
Generating the normalized data
The generation of the normalized data is performed using RabbitMQ message queues, and scala based workers.